| EANCOM® 2002 S3, Edition 2016 | Part I |

|
|
United Nation's Directories for Electronic Data Interchange for Administration, Commerce and Transport. They comprise a set of internationally agreed standards, directories and guidelines for the electronic interchange of structured data, particular as related to trade in goods and services, between independent, computerised information systems.
Recommended within the framework of the United Nations, the rules are approved and published by the UN/CEFACT (United Nations Centre for Trade Facilitation and Electronic business) in the United Nations Trade Data Interchange Directory (UNTDID) and are maintained under agreed procedures. UNTDID includes:
Actual information is available at http://www.unece.org/info/ece-homepage.html.
This section is a summary of the document: "EDIFACT - Application level syntax rules (Syntax version 3)". Actual information is available at www.unece.org/cefact.
The UN/EDIFACT syntax rules set the rules for structuring data into segments, segments into messages, and messages into an interchange.
An interchange may consist of the following segments:

Segments starting with "UN" are called service segments. They constitute the envelope or the "packaging" of the UN/EDIFACT messages.
User data segments contain the information itself, in a format specific to each message type.
Each data segment has a specific place within the sequence of segments in the message. They may occur in any of the following three sections of the message:
The sequence of the three message sections can be represented by the following simple example:
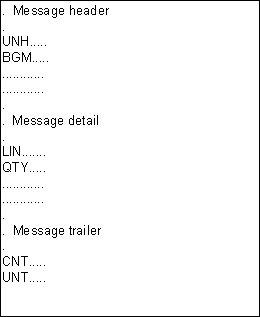
The same segment type may occur in more than one of the message sections, for example in the header and in the detail section, and/or more than once in the same section.
Some segments may be repeated a certain number of times at their specific location in the message. The status, Mandatory or Conditional, and the maximum number of repetitions of segment types are indicated in the message structure.
Within a message, specific groups of functionally related segments may be repeated; these groups are referred to as "segment groups". The maximum number of repetitions of a particular segment group at a specific location is included in the message definition.
A segment group may be nested within other segment groups, provided that the inner segment group terminates before any outer segment group terminates.
A segment consists of:
Data elements can be defined as having a fixed or variable length.
A composite data element contains two or more component data elements.
A component data element is a simple data element used in a composite data element.
Example of a composite data element:

The date qualifiers: function and value are the component data elements.
A data element can be qualified by another data element, the value of which is expressed as a code that gives specific meaning to the data. The data value of a qualifier is a code taken from an agreed set of code values.
Multiple occurrences of stand-alone simple or composite data elements are permitted.
In EANCOM®, four characters, extracted from character set level A, have a special meaning and act as the default service characters for EANCOM®:
|
Apostrophe |
' |
= segment terminator |
|
Plus sign |
+ |
= segment tag and data element separator |
|
Colon |
: |
= Component data element separator (separating simple data elements within a composite data element) |
|
Question mark |
? |
= Release character which, when immediately preceding one of the service characters, restores that character's normal meaning. For example, 10?+10=20 means 10+10=20. Question mark is represented by ?? |
Within EANCOM® 2002 syntax 3 the use of UNA is conditional.
Should trading partners agree to use any of the character sets from B to F (inclusive) and the default separators from UNOA, then the UNA segment must be provided to explicitly state the default separator values.
Example of an UN/EDIFACT segment:

In data elements for which the Trade Data Elements Directory specifies variable length and no other restrictions, non-significant character positions, (i.e. leading zeroes and trailing spaces) should be suppressed.
TAG = segment tag; DE = data element; CE = component data element.
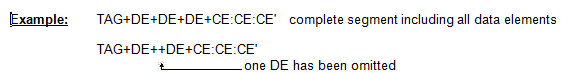

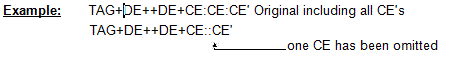
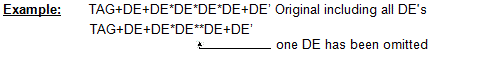
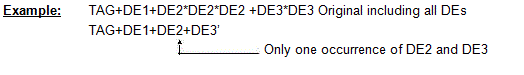
|
Numeric Class |
Format |
Integer Digit |
Decimal Digit |
|
Amounts |
n..18 |
12 |
6 |
|
Control Values |
n..18 |
14 |
4 |
|
Cubes |
n..9 |
5 |
4 |
|
Currency Rates |
n..12 |
6 |
6 |
|
Other Range Value |
n..18 |
15 |
3 |
|
Percentages |
n..10 |
6 |
4 |
|
Percentage Range Value |
n..18 |
14 |
4 |
|
Quantities |
n..15 |
12 |
3 |
|
Rate per Unit |
n..15 |
12 |
3 |
|
Tax Rates |
n..17 |
13 |
4 |
|
Unit Prices |
n..15 |
11 |
4 |
|
Unit Price Basis |
n..9 |
6 |
3 |
|
Weights |
n..18 |
15 |
3 |
Example 1 (INVOIC)

Example 2 (INVOIC)

As DE 5463 in the ALC segment contains code value A, the numeric values in MOA below should be interpreted as negative by the in-house application.
It is recommended to create one message for the invoice and one message for the credit note. As this is not always possible (e.g., an invoice for drinks with a negative deposit balance at detail level) the minus sign can be used in DE 6060 of the QTY segment and in DE 5004 of the MOA segment.
This rule is applicable for debit lines in credit notes and for credit lines in invoices/debit notes.
If allowances or charges are calculated backwards (credit note for a previously sent invoice) the code value in ALC DE 5463 is not changed.
Supported character sets
In syntax version 4 character sets level A, B, C, D, E, F, G, H, I, J, K, X and Y are supported. Also supported are the code extension techniques covered by ISO 2022 (with certain restrictions on its use within an interchange), and the partial use of the techniques covered by ISO/IEC 10646-1.
Within EANCOM® the use of character set level A is recommended. Any user, wishing to use a character set level other than A, should first obtain agreement from the intended trading partner in order to ensure correct processing by the receiving application.
Character set level A
Character set level A (ISO 646 7-bit single byte code, with the exception of lower case letters and certain graphic character allocations) contains the following characters:
|
Letters, upper case |
A to Z |
|
Numerals |
0 to 9 |
|
Space character |
|
|
Full stop |
. |
|
Comma |
, |
|
Hyphen/minus sign |
- |
|
Opening parentheses |
( |
|
Closing parentheses |
) |
|
Oblique stroke (slash) |
/ |
|
Equal sign |
= |
|
Exclamation mark |
! |
|
Quotation mark |
" |
|
Percentage sign |
% |
|
Ampersand |
& |
|
Asterisk |
* |
|
Semi-colon |
; |
|
Less-than sign |
< |
|
Greater-than sign |
> |
Character set level B
Character set level B (ISO 646 7-bit single byte code, with the exception of certain graphic character allocations) contains the same characters as character set level A plus lower case letters "a" to "z".
Character sets level C to F
Character sets level C to F (ISO 8859 - 1,2,5,7 8-bit single byte coded graphic character sets) cover the Latin 1 - 2, Cyrillic and Greek alphabets.
It is important to note that EANCOM® users often need, in addition to the recommended character set level A, the following sub-set of supplementary characters taken from ISO 8859 - 1:
|
Number sign |
# |
|
Commercial at |
@ |
|
Left square bracket |
[ |
|
Reverse solidus |
\ |
|
Right square bracket |
] |
|
Circumflex accent |
^ |
|
Grave accent |
` |
|
Left curly bracket |
{ |
|
Vertical line |
| |
|
Right curly bracket |
} |
Syntax identifier, ISO standard and supported languages
The following table contains the code values for the syntax identifier and explains which languages are catered for in which part of ISO-8859.
Note that the last character of the syntax identifier (data element 0001) identifies the character set level used.
|
Syntax identifier |
ISO standard |
Languages |
|
UNOA |
646 |
|
|
UNOB |
646 |
|
|
UNOC |
8859 - 1 |
Danish, Dutch, English, Faeroese, Finnish, French, German, Icelandic, Irish, Italian, Norwegian, Portuguese, Spanish, Swedish |
|
UNOD |
8859 - 2 |
Albanian, Czech, English, Hungarian, Polish, Romanian, Serbo-Croatian, Slovak, Slovene |
|
UNOE |
8859 - 5 |
Bulgarian, Byelorussian, English, Macedonian, Russian, Serbo-Croatian, Ukrainian |
|
UNOF |
8859 - 7 |
Greek |
All EANCOM® 2002 messages are based on the UN/EDIFACT directory D.01B, which was released by UN/CEFACT in 2001. All messages contained in this directory are approved as United Nations Standard Messages (UNSM).
Each EANCOM® message carries its own subset version number, which allows the unambiguous identification of different versions of the same EANCOM® message. The EANCOM® subset version number is indicated in data element 0057 in the UNG and UNH segments. It is structured as follows:
EANnnn
where:
EAN = EANCOM is the name of the standard, GS1 is the agency controlling the subset.
nnn = Three-digit version number of the EANCOM® subset.
Subset version numbers for formally released EANCOM® messages start at the number "001" and are incremented by one for each subsequent version of the message.
The following conventions apply in the present documentation:
|
Character type: |
|
|
a : |
alphabetic characters |
|
n : |
numeric characters |
|
an : |
alpha-numeric characters |
|
Size: |
|
|
Fixed : |
all positions must be used |
|
Variable : |
positions may be used up to a specified maximum |
|
Examples: |
|
|
a3 : |
3 alphabetic characters, fixed length |
|
n3 : |
3 numeric characters, fixed length |
|
an3 : |
3 alpha-numeric characters, fixed length |
|
a..3 : |
up to 3 alphabetic characters |
|
n..3 : |
up to 3 numeric characters |
|
an..3 : |
up to 3 alpha-numeric characters |
This section describes the layout of segments used in the EANCOM® messages. The original UN/EDIFACT segment layout is listed. The appropriate comments relevant to the EANCOM® subset are indicated.
The segments are presented in the sequence in which they appear in the message. The segment or segment group tag is followed by the (M)andatory / (C)onditional indicator, the maximum number of occurrences and the segment description.
Reading from left to right, in column one, the data element tags and descriptions are shown, followed by in the second column the UN/EDIFACT status (M or C), the field format, and the picture of the data elements. These first pieces of information constitute the original UN/EDIFACT segment layout.
Following the UN/EDIFACT information, EANCOM® specific information is provided in the third, fourth, and fifth columns. In the third column a status indicator for the use of (C)onditional UN/EDIFACT data elements (see description below), in the fourth column the restriction indicator, and in the fifth column notes and code values used for specific data elements in the message.
Status indicators
(M)andatory data elements or composites in UN/EDIFACT segments retain their status in EANCOM®.
Additionally, there are five types of status with a (C)onditional UN/EDIFACT status, whether for simple, component or composite data elements. They are listed below and can be identified when relevant by the abbreviations.
|
|
REQUIRED |
R |
- |
Indicates that the entity is required and must be sent. |
|
|
ADVISED |
A |
- |
Indicates that the entity is advised or recommended. |
|
|
DEPENDENT |
D |
- |
Indicates that the entity must be sent in certain conditions, as defined by the relevant explanatory note. |
|
|
OPTIONAL |
O |
- |
Indicates that the entity is optional and may be sent at the discretion of the user. |
|
|
NOT USED |
N |
- |
Indicates that the entity is not used and should be omitted. |
If a composite is flagged as N, NOT USED, all data elements within that composite will have blank status indicators assigned to them.
Different colours are used for the code values in the HTML segment details: restricted codes are in red and open codes in blue.
Within every EANCOM® message two diagrams are presented which explain the structure and sequence of the message. These diagrams are known as the Message Structure Chart and the Message Branching Diagram.
The message structure chart is a sequential chart which presents the message in the sequence in which it must be formatted for transmission. Every message is structured and consists of three sections; a header, detail, and summary section. An example of a message structure chart follows:
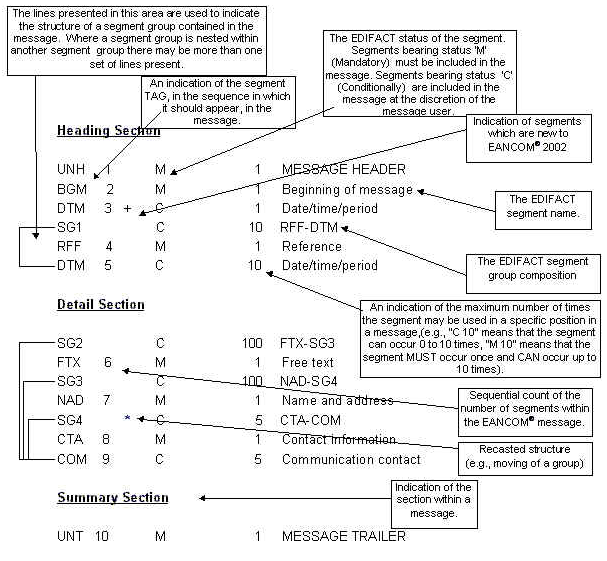
The structure chart should always be read from top down and left to right (please note that the message detailed is simply an example message and does not bear any relevance to real EANCOM® messages).
A message branching diagram is a pictorial representation (in flow chart style) which presents the logical sequence and relationships contained within a message.
Branching diagrams should be read, starting at the UNH segment, from left to right and top to bottom. The lines contained within a branching diagram should be considered as guides that must be followed in order to progress through the message.

The interchange structure in an UN/EDIFACT transmission is organised through several grouping levels. The service segments are the envelope of the groups.
The first service segment possible in an interchange is the "UNA" segment which defines the service characters being used in the interchange.
The second service segment, "UNB", indicates the beginning of the interchange.
The next one, "UNG", indicates the beginning of a group of messages of the same type, or to create own identifiable application level envelope.
The last service segment, "UNH", indicates the beginning of a given message.
Each beginning service segment corresponds to an ending service segment (note: UNA is not a beginning segment).
The interchange can thus be represented like this:
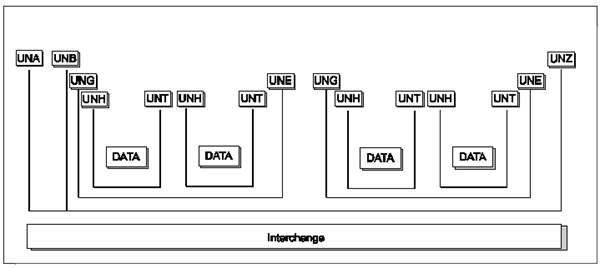
The status of segment UNA is dependent on the character set level and service characters being used. If character set level A is being used together with the default service characters for EANCOM® then the UNA segment is not required. However, should trading partners agree to use any of the character sets level B to F (inclusive) and the default service characters for EANCOM®, then the UNA segment must be sent.
Segments UNB..UNZ and UNH..UNT are mandatory.
Segments UNG..UNE are conditional. Within EANCOM® the use of the UNG..UNE segments should not be used for grouping of multiple message types in the same interchange as this is not considered good practice. However, they can be used by organisations to create their own identifiable application level envelopes, which can be addressed from the originating department to a department in the recipient's system, e.g. to group multiple issuers in one transmission file with invoices.
If the UNG..UNE segments are used, then it should be noted that it is not possible in the EANCOM® CONTRL message to report syntactically on a functional group.
The message itself is structured with a Header, a Detail and a Summary section. In messages where there may be ambiguity between the sections, the UNS segment may be used as a separator.
The layout of the service segments UNA, UNB - UNZ, UNG - UNE, and UNH - UNT- used in EANCOM® is presented in this section. The Section Control Segment (UNS) is not shown here. Its usage is defined in those EANCOM® messages where the segment is actually used.
Segment Layout - UNA segment
|
UNA - C 1 - |
Service String Advice |
|||||
|
Function : |
The service string advice shall begin with the upper case characters UNA immediately followed by six characters in the order shown below. The same character shall not be used in more than one position of the UNA. |
|||||
|
Segment number : |
|
|||||
|
|
EDIFACT |
GS1 |
* |
Description |
||
|
UNA1 |
Component data element separator |
M an1 |
M |
* |
Used as a separator between component data elements contained within a composite data element (default value: ":") |
|
|
UNA2 |
Data element separator |
M an1 |
M |
* |
Used to separate two simple or composite data elements (default value: "+" ) |
|
|
UNA3 |
Decimal notation |
M an1 |
M |
* |
Used to indicate the character used for decimal notation (default value:".") |
|
|
UNA4 |
Release character |
M an1 |
M |
* |
Used to restore any service character to its original specification (value: "?"). |
|
|
UNA5 |
Reserved for future use |
M an1 |
M |
* |
(default value: space ) |
|
|
UNA6 |
Segment terminator |
M an1 |
M |
* |
Used to indicate the end of segment data (default value: " ' ") |
|
|
Segment Notes: This segment is used to inform the receiver of the interchange that a set of service string characters which are different to the default characters are being used. When using the default set of service characters, the UNA segment need not be sent. If it is sent, it must immediately precede the UNB segment and contain the four service string characters (positions UNA1, UNA2, UNA4 and UNA6) selected by the interchange sender. Regardless of whether or not all of the service string characters are being changed every data element within this segment must be filled, (i.e., if some default values are being used with user defined ones, both the default and user defined values must be specified). When expressing the service string characters in the UNA segment, it is not necessary to include any element separators. The use of the UNA segment is required when using a character set other than level A. Example: |
||||||
Segment Layout - UNB segment
|
UNB - M 1 - |
Interchange Header |
|||||
|
Function : |
To start, identify and specify an interchange. |
|||||
|
Segment number : |
|
|||||
|
|
EDIFACT |
GS1 |
* |
Description |
||
|
S001 |
SYNTAX IDENTIFIER |
M |
M |
. |
See Part I chapter 5.2.7 and segment notes. |
|
|
0001 |
Syntax identifier |
M a4 |
M |
* |
UNOA = UN/ECE level A |
|
|
0002 |
Syntax version number |
M n1 |
M |
* |
3 = Version 3 |
|
|
S002 |
INTERCHANGE SENDER |
M |
M |
. |
||
|
0004 |
Sender identification |
M an..35 |
M |
. |
GLN (n13) |
|
|
0007 |
Partner identification code qualifier |
C an..4 |
R |
* |
14 = GS1 |
|
|
0008 |
Address for reverse routing |
C an..14 |
O |
. |
||
|
S003 |
INTERCHANGE RECIPIENT |
M |
M |
. |
||
|
0010 |
Interchange recipient identification |
M an..35 |
M |
. |
GLN (n13) |
|
|
0007 |
Partner identification code qualifier |
C an..4 |
R |
* |
14 = GS1 |
|
|
0014 |
Interchange recipient internal |
C an..14 |
O |
. |
||
|
S004 |
DATE AND TIME OF |
M |
M |
. |
||
|
0017 |
Date of preparation |
M n6 |
M |
. |
YYMMDD |
|
|
0019 |
Time of preparation |
M n4 |
M |
. |
HHMM |
|
|
0020 |
Interchange control reference |
M an..14 |
M |
. |
Unique reference identifying the interchange. Created by the interchange sender. |
|
|
S005 |
RECIPIENT REFERENCE/ PASSWORD DETAILS |
C |
O |
. |
||
|
0022 |
Recipient reference/password |
M an..14 |
M |
. |
||
|
0025 |
Recipient reference/password qualifier |
C an2 |
O |
. |
||
|
0026 |
Application reference |
C an..14 |
O |
. |
Message identification if the interchange contains only one type of message. |
|
|
0029 |
Processing priority code |
C a1 |
O |
. |
A = Highest priority |
|
|
0031 |
Acknowledgement request |
C n1 |
O |
. |
1 = Requested |
|
|
0032 |
Interchange agreement identifier |
C an..35 |
O |
* |
EANCOM...... |
|
|
0035 |
Test indicator |
C n1 |
O |
. |
1 = Interchange is a test |
|
|
Segment notes : This segment is used to envelope the interchange, as well as to identify both, the party to whom the interchange is sent and the party who has sent the interchange. The principle of the UNB segment is the same as a physical envelope which covers one or more letters or documents, and which details, both the address where delivery is to take place and the address from where the envelope has come. DE 0001: The recommended (default) character set for use in EANCOM® for international exchanges is DE 0004 and 0010: Within EANCOM® the use of the Global Location Number (GLN), is recommended for the identification of the interchange sender and recipient. DE 0008: The address for reverse routing is provided by the interchange sender to inform the interchange recipient of the address within the sender’s system to which responding interchanges must be sent. It is recommended that the GLN be used for this purpose. DE 0014: The address for routing, provided beforehand by the interchange recipient, is used by the inter-change sender to inform the recipient of the internal address, within the latter’s systems, to which the interchange should be routed. It is recommended that the GLN be used for this purpose. DE S004: The date and time specified in this composite should be the date and time at which the inter-change sender prepared the interchange. This date and time may not necessarily be the same as the date and time of contained messages. DE 0020: The interchange control reference number is generated by the interchange sender and is used to DE S005: The use of passwords must first be agreed bilaterally by the parties exchanging the interchange. DE 0026: This data element is used to identify the application, on the interchange recipient’s system, to which the interchange is directed. This data element may only be used if the interchange contains only one type of message, (e.g. only invoices). The reference used in this data element is assigned by the interchange sender. DE 0031: This data element is used to indicate whether an acknowledgement to the interchange is required. DE 0032: This data element is used to identify any underlying agreements which control the exchange of Example : UNB+UNOA:3+5412345678908:14+8798765432106:14+020102:1000+12345555+++++EANCOMREF 52' |
||||||
Segment Layout - UNG segment
|
UNG - C 1 - |
Functional Group Header |
|||||
|
Function : |
To start, identify and specify a functional group. |
|||||
|
Segment number : |
|
|||||
|
|
EDIFACT |
GS1 |
* |
Description |
||
|
0038 |
FUNCTIONAL GROUP IDENTIFICATION |
M an..6 |
M |
|
Identification of a message contained in the functional group, e.g. INVOIC. |
|
|
S006 |
APPLICATION SENDER’S IDENTIFICATION |
M |
M |
|
|
|
|
0040 |
Sender identification |
M an..35 |
M |
|
GLN (n13) |
|
|
0007 |
Identification code qualifier |
C an..4 |
R |
* |
14 = GS1 |
|
|
S007 |
INTERCHANGE RECIPIENT |
M |
M |
|
|
|
|
0044 |
Recipient identification |
M an..35 |
M |
|
GLN (n13) |
|
|
0007 |
Identification code qualifier |
C an..4 |
R |
* |
14 = GS1 |
|
|
S004 |
DATE / TIME OF PREPARATION |
M |
M |
|
|
|
|
0017 |
Date |
M n6 |
M |
|
YYMMDD |
|
|
0019 |
Time |
M n4 |
M |
|
HHMM |
|
|
0048 |
Functional group reference number |
M an..14 |
M |
|
Unique reference identifying the functional group. Created by the interchange sender. |
|
|
0051 |
Controlling agency |
M an..2 |
M |
* |
UN = UN/CEFACT |
|
|
S008 |
MESSAGE VERSION |
M |
M |
|
|
|
|
0052 |
Message type version number |
M an..3 |
M |
* |
D = UN/EDIFACT directory |
|
|
0054 |
Message type release number |
M an..3 |
M |
|
The value of this data element depends on the message type. |
|
|
0057 |
Association assigned code |
C an..6 |
R |
|
The value of this data element depends on the message type. |
|
|
0058 |
Application password |
C an..14 |
D |
|
The use of this data element depends on agreements between the trading partners. |
|
|
Segment notes : Within EANCOM® the use of the UNG..UNE segments should not be used for grouping of multiple message types in the same interchange as this is not considered good practice. However, they can be used by organisations to create their own identifiable application level envelopes, which can be addressed from the originating department to a department in the recipient's system, e.g. to group multiple issuers in one transmission file with invoices. Example : UNG+INVOIC+5412345678908:14+8798765432106:14+020102:1000+471123+UN+D:01B:EAN010' |
||||||
Segment Layout - UNH segment
|
UNH - M 1 - |
MESSAGE HEADER |
|||||
|
Function : |
To head, identify and specify a message. |
|||||
|
Segment number : |
|
|||||
|
|
EDIFACT |
GS1 |
* |
Description |
||
|
0062 |
Message reference number |
M an..14 |
M |
Unique reference number assigned to a message within an interchange by the sender. Same reference number as in DE 0062 of the UNT segment of the message. |
||
|
S009 |
MESSAGE IDENTIFIER |
M |
M |
|||
|
0065 |
Message type |
M an..6 |
M |
* |
Identification of a message. |
|
|
0052 |
Message version number |
M an..3 |
M |
* |
D = UN/EDIFACT Directory |
|
|
0054 |
Message release number |
M an..3 |
M |
* |
01B = Release 2001 - B |
|
|
0051 |
Controlling agency |
M an..2 |
M |
* |
UN = UN/CEFACT |
|
|
0057 |
Association assigned code |
C an..6 |
R |
* |
EANnnn = EANCOM® subset version. EAN represents GS1. "nnn" is the subset version number of the EANCOM® message. |
|
|
0068 |
Common access reference |
C an..35 |
N |
|||
|
S010 |
STATUS OF THE |
C |
N |
|||
|
0070 |
Sequence of transfers |
M n..2 |
||||
|
0073 |
First and last transfer |
C a1 |
|
|||
|
Segment Notes : This segment is used to head and uniquely identify a message in an interchange. DE 0062: It is good practice to have the message reference number both unique and incremental. S009: Identification of an EANCOM® message. The content of data elements 0065, 0052, 0054 and 0051 must be taken from the related UN/EDIFACT standard message. The content of data element 0057 is assigned by GS1 as part of the EANCOM® maintenance process. DE 0065: Data element 0065 identifies a UN/EDIFACT message whereas the exact usage of the message is specified in BGM data element 1001. E.g. UN/EDIFACT invoice message serving as a credit note: UNH DE 0065 = INVOIC, BGM DE 1001 = 381. The combination of the values carried in the data elements 0062 and S009 shall be used to uniquely identify the message within the interchange for the purpose of acknowledgement (ref. UNB - data element 0031). Example : UNH+1+INVOIC:D:01B:UN:EAN010' |
||||||
Segment Layout - UNT segment
|
UNT - M 1 - |
MESSAGE TRAILER |
|||||
|
Function : |
To end and check the completeness of a message. |
|||||
|
Segment number : |
||||||
|
|
EDIFACT |
GS1 |
* |
Description |
||
|
0074 |
Numberof segments in the message |
M n..6 |
M |
. |
Total number of segments in a message. |
|
|
0062 |
Messagereference number |
M an..14 |
M |
. |
Same reference number as in DE 0062 of the UNH segment of the message. |
|
|
Segment Notes : This segment is used to end and provide information for checking the completeness of a message. The segment number shows the position of the segment in a message. It must always be the last segment in a message. DE 0074: Count of all segments in a message, UNH and UNT included. Example : UNT+103+1' |
||||||
Segment Layout - UNE segment
|
UNE - C 1 - |
FUNCTIONAL GROUP TRAILER |
|||||
|
Function : |
To end and check the completeness of a functional group. |
|||||
|
Segment number : |
|
|||||
|
|
EDIFACT |
GS1 |
* |
Description |
||
|
0060 |
Number of messages |
M n..6 |
M |
|
Number of messages in the group. |
|
|
0048 |
Functional group reference number |
M an..14 |
M |
|
Identical to DE 0048 in UNG segment. |
|
|
Segment Notes : Within EANCOM® the use of the UNG..UNE segments should not be used for grouping of multiple message types in the same interchange as this is not considered good practice. However, they can be used by organisations to create their own identifiable application level envelopes, which can be addressed from the originating department to a department in the recipient's system, e.g. to group multiple issuers in one transmission file with invoices. Example : UNE+25+471123' |
||||||
Segment Layout - UNZ segment
|
UNZ - M 1 - |
INTERCHANGE TRAILER |
|||||
|
Function : |
To end and check the completeness of an interchange. |
|||||
|
Segment number : |
||||||
|
|
EDIFACT |
GS1 |
* |
Description |
||
|
0036 |
Interchange control count |
M n..6 |
M |
. |
Number of messages or functional groups within an interchange. |
|
|
0020 |
Interchange control reference |
M an..14 |
M |
. lang=EN-GB style='color:red'> |
Identical to DE 0020 in UNB segment. |
|
|
Segment Notes : This segment is used to provide the trailer of an interchange. DE 0036: If functional groups are used, this is the number of functional groups within the interchange. If functional groups are not used, this is the number of messages within the interchange. Example : UNZ+5+12345555' |
||||||
Example of an interchange:
An interchange contains two sets of messages: three Despatch Advices and two Invoices. The interchange is sent on 2 January 2002 by a company identified by the GLN 5412345678908 to a company identified by the GLN 8798765432106.

|